In the paper DeepSeek-OCR: Contexts Optical Compression, the authors proposed a novel approach to transform long LLM contexts into images as a form of compression. The core idea is to encode long textual context as an image before sending it to an LLM in order to save on the number of textual tokens sent to an LLM as images use less tokens and can encode more textual information compared to text alone. Optical compression through the use of vision tokens can result in higher compression ratios.
DeepSeek-OCR is a new architecture that supports this approach described above. It consists of the following components:
- DeepEncoder
- Decoder
Firstly, an image input is converted into 16x16 patches, similar to how Vision Transformers work. The patches are sent as input into the encoder. The encoder is responsible for extracting image features and apply compression to visual representations.
The DeepEncoder consists of 2 main models connected sequentially:
- SAM-Base 80M model
- CLIP-Large 300M model
The image below shows the architecture of the DeepSeek-OCR model:
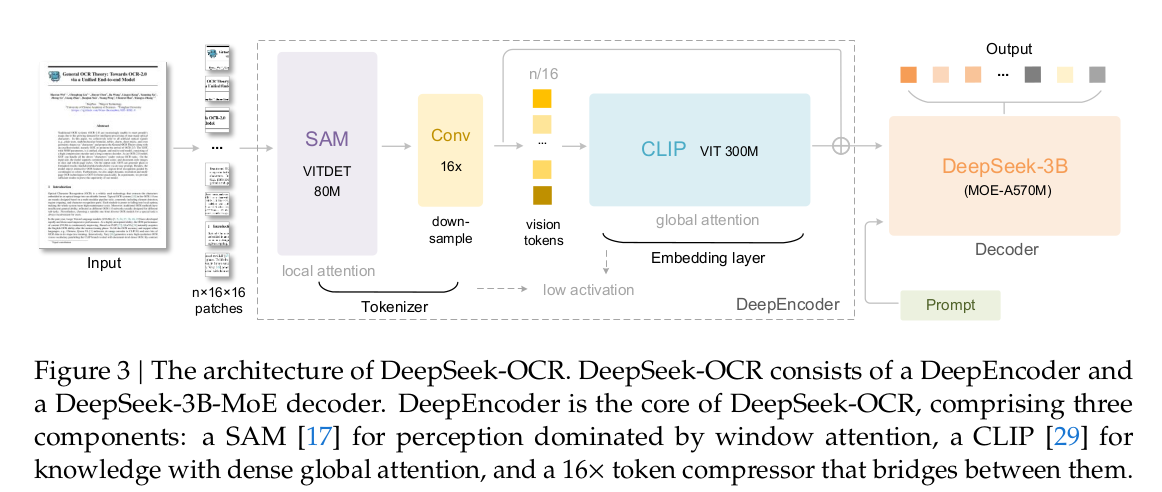
Between the two vision models are 2 additional convolutional layers which the paper labeled as compressors that performs further downsampling of the vision tokens.
The idea is that the SAM ViT model outputs vision tokens ( local / self attention ) which the compressor downsamples before they are sent to the CLIP model to apply global attention to, which becomes the embedding layer. The first patch embedding layer from the CLIP model is removed to achieve this.
Since the 2 layer convolutional kernel performs 16x downsampling, a single 1024x1024 image can result in only 256 tokens.
The decoder is a DeepSeek-3B model which uses a MoE architecture. During inference, the model can activate 6 out of 64 routed experts and 2 shared experts with about 570M activated parameters. The model is chosen as it has the efficiency of a small language model.
The decoder tries to reconstruct the original text representation from the compressed latent vision tokens output from the DeepEncoder and learns a non-linear mapping through OCR-style training approaches.
In terms of training, the entire architecture is trained as an end-to-end OCR model. The training dataset is carefully curated to include a mix of OCR as well as text and image data. 4 sets of data are curated as follows:
- OCR 1.0, which consists of traditional OCR tasks such as scene image and document OCR
- OCR 2.0, which includes generated charts, formulas and plane geometry with annotations
- General vision data
- Text-only data
For OCR 1.0 dataset, the authors curated 30M pages of PDF data which includes over 100 languages collected from the Internet.
For OCR 2.0 dataset, over 10M synthetic images of charts such as bar and composite charts are created using pyechatys and matplotlib. The dataset also includes chemical formulas using the SMILES format from PubChem as data source. Additional plane geometry images are also created via Slow Perception which has data augmentation applied in the form of geometric translation-invariant transforms, resultig in an additional 1M images.
A similar approach of using techniques in DeepSeek-VL2 was used to generate general vision data for tasks such as captioning, detection and grounding.
Another dataset of text-only data is also created in-house and contains only text. All the text data is processed to be of length 8192 tokens which is the same sequence length of DeepSeek-OCR
For evaluation, the authors evaluated the model using the following conditions:
- Compression-decompression
- Document parsing
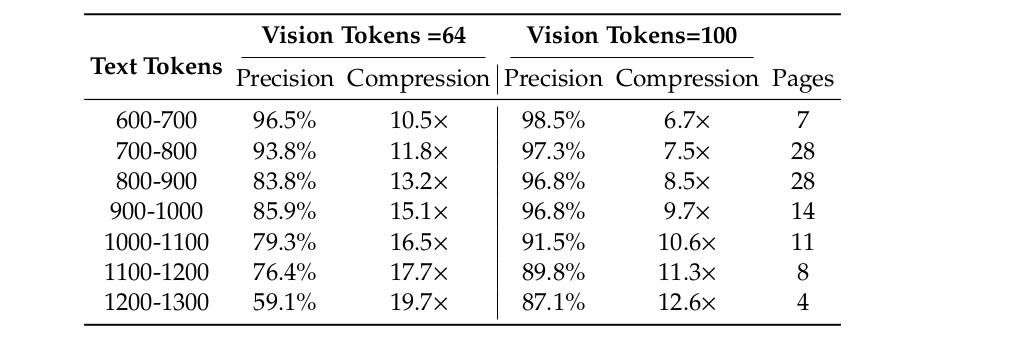
In terms of evaluating compression-decompression, only documents with tokens from 600 to 1300 from the English portion of the Fox benchmark was used for evaluation. A single prompt of “
The table below shows the compression-decompression results:
For evaluating document parsing, the model was evaluated against the OmniDocBench benchmark, which is a benchmark for evaluating diverse document parsing in real-world scenarios. With only 100 vision tokens at 640x640 resolution, the model surpasses GOT-OCR2.0 which requires 256 tokens. The results also show that different types of documents require fewer tokens to achieve good results e.g. for books and documents, the model can achieve good performance with only 100 vision tokens. For newspapers with longer texts, more tokens are required for compression.
An additional set of qualitative studies are also carried out:
- Deep Parsing
- Multilingual recognition
- General vision understanding
For deep parsing, the OCR 2.0 dataset allows the model to accept prompts to parse images within documents through secondary model calls. It can extract charts, geometry and chemical formulas with a unified prompt. For books and documents, deep parsing can output dense captions for natural images in documents. Using prompts, the model can automatically identity what type of image and it is and output the required results.
In terms of multilingual recognition, the model has been trained on over 100 different languages and can show that it can recognise layout and multilingual text for different languages.
For general vision understanding, the model has been trained on an additional set of syntheic images and as such, it is able to identity and extract images from within images using prompts.
The paper shows the promise of using vision tokens to compress complex textual information. One good use of this could be in the compression of long, multi-turn histories with LLM interactions.
The paper also points out that using OCR evaluation techniques alone is insufficient to fully validate the context-optical compression and other more detailed evaluations are required for future studies.
@misc{wei2025deepseekocrcontextsopticalcompression,
title={DeepSeek-OCR: Contexts Optical Compression},
author={Haoran Wei and Yaofeng Sun and Yukun Li},
year={2025},
eprint={2510.18234},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.18234},
}