In a previous post, I provided a brief introduction to Triton server for deploying ML models and how to run an ensemble model locally using Docker. In this post, I aim to explain my process for deploying Trition in AWS and how to perform inference using the deployed endpoint.
This post will use the Triton inference server python backend as an example.
The ensemble model created had several dependencies. As documented under Creating custom execution env, we can use conda and conda-pack to create the deployment package. We need to do this from within the same Trition docker container used for development. Firstly, we start a Triton docker container and mount the model’s directory as a volume. Next, we install conda and run a custom shell script to create the standalone conda environment. Note that the version of python created in the standalone environment must match the python version in the container. Since all Triton docker images use python 3.10 by default, we create a new conda environment based on that same version.
As of this writing, there was an issue with using Triton client library and numpy. We restrict the numpy version to 1.26.4
Given a running Triton container, we use docker exec to start an interactive bash shell and install Miniconda:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.shNext, we create a custom conda environment with the required dependencies:
#!/usr/bin/env bash
eval "$(/root/miniconda3/bin/conda shell.bash hook)"
# NOTE: Below needs to be run within a triton container
# triton 23.12 uses python 3.10.12 so we limit to that python version
# if not we need to build a custom python backend stub
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/r
conda create -y -n py310 python=3.10.12
conda init
conda activate py310
# FIX numpy at version 1.26.4 due to: https://github.com/triton-inference-server/server/issues/7391
conda install -c conda-forge libstdcxx-ng=12 -y
export PYTHONNOUSERSITE=True
pip install numpy==1.26.4 transformers==4.51.3 torch==2.7.0 pillow==11.2.1 opencv-python-headless scikit-image scipy boto3 conda-pack
conda-pack
mkdir -p model_repository/detection_postprocessing/py310
tar -xvf py310.tar.gz -C model_repository/detection_postprocessing/py310
rm -rf py310.tar.gzThis script creates a conda environment running python 3.10.12. We need to set PYTHONUSERSITE to be true to ensure all the deps are installed into the conda environment. After installation, we call conda-pack to package the python version and its depedencies into a standalone environment. This will create a TAR archive of the same name as the conda environment, namely py310.tar.gz. We extract this archive into one of the model’s directory. This allows other models in the same directory to reuse the same execution environment. For instance, assuming we have the following model directory structure:
model_repository/
├── detection_postprocessing
│ ├── 1
│ │ └── model.py
│ ├── py310
│ └── config.pbtxt
├── ensemble_model
│ ├── 1
│ └── config.pbtxt
├── grounding_dino_tiny
│ ├── 1
│ │ └── model.py
│ └── config.pbtxt
└── sam_vit
├── 1
│ └── model.py
└── config.pbtxtThe custom conda environment ( py310 ) is extracted into the first model detection_postprocessing sub-directory. It’s config.pbtxt file has a reference to it via the EXECUTION_ENV_PATH env variable:
name: "detection_postprocessing"
backend: "python"
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "$$TRITON_MODEL_DIRECTORY/py310"}
}
...If the model sam_vit wants to use the same custom env, it will need to reference it also in its config.pbtxt file with a relative reference to it:
name: "sam_vit"
backend: "python"
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "$$TRITON_MODEL_DIRECTORY/../detection_postprocessing/py310"}
}Deploy into SageMaker Inference
To deploy the models into SageMaker Inference, we need to create a TAR archive of the entire model directory. This TAR archive will be uploaded into S3 and extracted when we create the Inference endpoint. As such, no symlinks can exist else the model creation will fail during endpoint creation. Below is a custom script I used to address this issue:
#!/usr/bin/env bash
# Check if a directory is provided as an argument
if [ $# -eq 0 ]; then
echo "Usage: $0 <directory>"
exit 1
fi
# The directory to process
dir="$1"
# Find all symbolic links in the directory and its subdirectories
find "$dir" -type l | while read -r link; do
# Get the target of the symbolic link
target=$(readlink -f "$link")
# Check if the target file exists
if [ -e "$target" ]; then
# Remove the symbolic link
rm "$link"
# Copy the actual file to the location of the former symbolic link
cp -a "$target" "$link"
echo "Replaced symlink: $link"
else
echo "Warning: Target does not exist for $link"
fi
doneThe script above will replace all symlinks it finds in a given directory and replaces it with the actual file.
The next step is to create the actual archive of the model directory. This may take some time to run due to the size of the created environment:
tar --exclude="hf_cache" -cvzf ensemble_model.tar.gz -C model_repository/ detection_postprocessing ensemble_model grounding_dino_tiny sam_vitOnce completed, we upload the created archive into S3. We use the default sagemaker bucket created. We could also perform the upload during the inference endpoint deployment but it could take longer:
aws s3 cp ensemble_model.tar.gz s3://sagemaker-<region>-<account id>/ensemble_model.tar.gzFinally, we create the SageMaker inference endpoint. I used the boto3 library following an example from the official Sagemaker notebook:
sm_client = boto3.client(service_name="sagemaker")
runtime_sm_client = boto3.client("sagemaker-runtime")
sagemaker_session = sagemaker.Session(boto_session=boto3.Session())
bucket = sagemaker.Session().default_bucket()
prefix = "ensemble_model"
default_bucket_prefix = sagemaker.Session().default_bucket_prefix
if default_bucket_prefix:
prefix = f"{default_bucket_prefix}/{prefix}"
# account mapping for SageMaker MME Triton Image
account_id_map = {
"us-east-1": "785573368785",
"us-east-2": "007439368137",
"us-west-1": "710691900526",
"us-west-2": "301217895009",
"eu-west-1": "802834080501",
"eu-west-2": "205493899709",
"eu-west-3": "254080097072",
"eu-north-1": "601324751636",
"eu-south-1": "966458181534",
"eu-central-1": "746233611703",
"ap-east-1": "110948597952",
"ap-south-1": "763008648453",
"ap-northeast-1": "941853720454",
"ap-northeast-2": "151534178276",
"ap-southeast-1": "324986816169",
"ap-southeast-2": "355873309152",
"cn-northwest-1": "474822919863",
"cn-north-1": "472730292857",
"sa-east-1": "756306329178",
"ca-central-1": "464438896020",
"me-south-1": "836785723513",
"af-south-1": "774647643957",
}
region = boto3.Session().region_name
if region not in account_id_map.keys():
raise("Unsupported region")
base = "amazonaws.com.cn" if region.startswith("cn-") else "amazonaws.com"
account_id = account_id_map[region]
image_uri = f"{account_id}.dkr.ecr.{region}.{base}/sagemaker-tritonserver:23.12-py3"
# model_uri_pytorch = sagemaker_session.upload_data(path="ensemble_model.tar.gz", key_prefix=prefix)
model_data_url = "s3://sagemaker-eu-west-2-<account id>/ensemble_model.tar.gz"
container = {
"Image": image_uri,
"ModelDataUrl": model_data_url,
"Environment": {"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME": "ensemble_model"}
}
ts = time.strftime("%Y-%m-%d-%H-%M-%S", time.gmtime())
sm_model_name = f"ensemble-{ts}"
role = "arn:aws:iam::<account id>:role/SageMakerExecutionRole"
create_model_response = sm_client.create_model(
ModelName=sm_model_name,
ExecutionRoleArn=role,
PrimaryContainer=container
)
print(f"Model Arn: {create_model_response["ModelArn"]}")
endpoint_config_name = f"ensemble-epc-{ts}-2xl"
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"InstanceType": "ml.g5.2xlarge",
"InitialVariantWeight": 1,
"InitialInstanceCount": 1,
"ModelName": sm_model_name,
"VariantName": "AllTraffic",
}
],
)
print("Endpoint Config Arn: " + create_endpoint_config_response["EndpointConfigArn"])
endpoint_name = f"ensemble-ep-{ts}-2xl"
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)
print("Endpoint Arn: " + create_endpoint_response["EndpointArn"])
resp = sm_client.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
print("Status: " + status)
while status == "Creating":
time.sleep(60)
resp = sm_client.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
print("Status: " + status)
print("Arn: " + resp["EndpointArn"])
print("Status: " + status)The script creates a SageMaker session client object. Next, it maps the region of the deployment to an AWS account id in order to create the full docker image uri of the Triton server. In this example, we are using the same version we used previously for localhost development which is sagemaker-tritonserver:23.12-py3. This docker image is used to create the inference model via sm_client.create_model. Note that we set the SAGEMAKER_TRITON_DEFAULT_MODEL_NAME to match that of the ensemble model name defined in the model respository, which is ensemble_model.
After the model is deployed, we create an endpoint config using client.create_endpoint_config where we specify the inference instance type and number of instances to launch. We create the inference endpoint using sm_client.create_endpoint.
Note that the IAM role used to create the model needs to assume the sagemaker.amazonaws.com trust policy and have IAM permissions of AmazonSageMakerFullAccess. Even though this policy allows for S3 access to any bucket with sagemaker in its name, I was unable to create a deployment successfully due to permission issues. I ended up adding extra inline policy to grant permission to access the target bucket where we uploaded the model repository TAR file.
When completed, the endpoint would show as being InService as shown in the screenshots below.
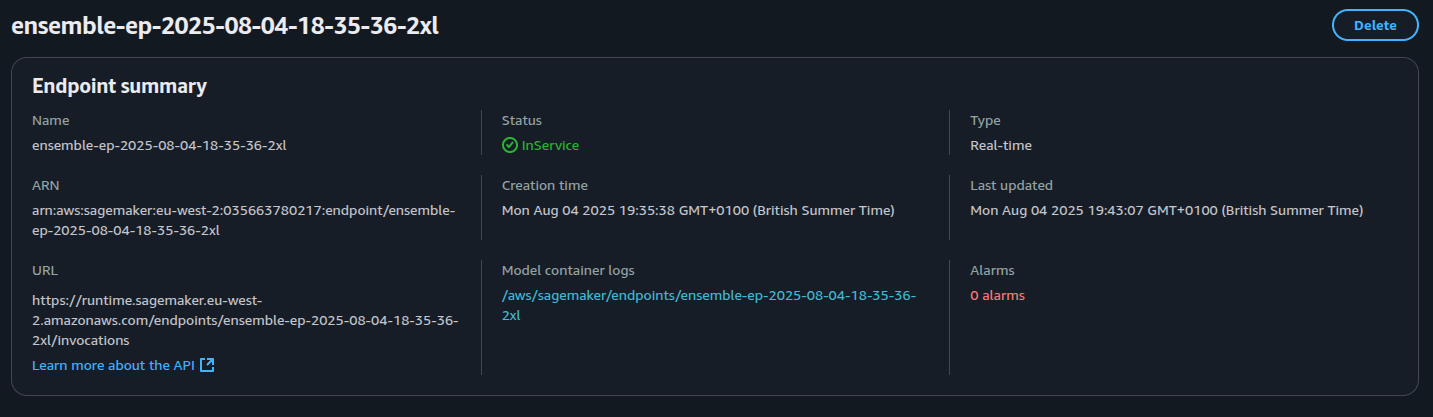
The Sagemaker endpoint automatically creates Cloudwatch Metrics such as CPU and memory utilisation as well as a Cloudwatch log group. An example of a successful deployment is shown in the logs below:
I0804 18:42:27.090811 93 python_be.cc:2363] TRITONBACKEND_ModelInstanceInitialize: grounding_dino_tiny_0 (GPU device 0)
I0804 18:42:27.091050 93 backend_model_instance.cc:106] Creating instance grounding_dino_tiny_0 on GPU 0 (8.6) using artifact 'model.py'
I0804 18:42:27.091132 93 pb_env.cc:264] Returning canonical path since EXECUTION_ENV_PATH does not contain compressed path. Path: /opt/ml/model/detection_postprocessing/py310
I0804 18:42:27.093830 93 stub_launcher.cc:253] Starting Python backend stub: source /opt/ml/model/detection_postprocessing/py310/bin/activate && exec env LD_LIBRARY_PATH=/opt/ml/model/detection_postprocessing/py310/lib:$LD_LIBRARY_PATH /opt/tritonserver/backends/python/triton_python_backend_stub /opt/ml/model/grounding_dino_tiny/1/model.py triton_python_backend_shm_region_6 16777216 1048576 93 /opt/tritonserver/backends/python 336 grounding_dino_tiny_0 DEFAULT
I0804 18:42:34.966462 93 model.py:26] Loading HuggingFace model: facebook/sam-vit-base
I0804 18:42:34.992955 93 model.py:25] Loading HuggingFace model: IDEA-Research/grounding-dino-tiny
I0804 18:42:39.505874 93 python_be.cc:2384] TRITONBACKEND_ModelInstanceInitialize: instance initialization successful sam_vit_0 (device 0)
I0804 18:42:39.505952 93 backend_model_instance.cc:772] Starting backend thread for sam_vit_0 at nice 0 on device 0...
I0804 18:42:39.506200 93 model_lifecycle.cc:818] successfully loaded '/opt/ml/model/::sam_vit'
I0804 18:42:40.464541 93 python_be.cc:2384] TRITONBACKEND_ModelInstanceInitialize: instance initialization successful grounding_dino_tiny_0 (device 0)
I0804 18:42:40.464626 93 backend_model_instance.cc:772] Starting backend thread for grounding_dino_tiny_0 at nice 0 on device 0...
I0804 18:42:40.464875 93 model_lifecycle.cc:818] successfully loaded '/opt/ml/model/::grounding_dino_tiny'
I0804 18:42:40.465080 93 model_lifecycle.cc:461] loading: /opt/ml/model/::ensemble_model:1
I0804 18:42:40.465243 93 ensemble_model.cc:55] ensemble model for ensemble_model
I0804 18:42:40.465264 93 model_lifecycle.cc:818] successfully loaded '/opt/ml/model/::ensemble_model'
I0804 18:42:40.465380 93 server.cc:606]
+------------------+------+
| Repository Agent | Path |
+------------------+------+
+------------------+------+
I0804 18:42:40.465435 93 server.cc:633]
+---------+-------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Backend | Path | Config |
+---------+-------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| python | /opt/tritonserver/backends/python/libtriton_python.so |
{
"cmdline": {
"auto-complete-config": "true",
"backend-directory": "/opt/tritonserver/backends",
"min-compute-capability": "6.000000",
"shm-default-byte-size": "16777216",
"shm-growth-byte-size": "1048576",
"default-max-batch-size": "4"
}
}
|
+---------+-------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
I0804 18:42:40.465474 93 server.cc:676]
+------------------------------------------+---------+--------+
| Model | Version | Status |
+------------------------------------------+---------+--------+
| /opt/ml/model/::detection_postprocessing | 1 | READY |
| /opt/ml/model/::ensemble_model | 1 | READY |
| /opt/ml/model/::grounding_dino_tiny | 1 | READY |
| /opt/ml/model/::sam_vit | 1 | READY |
+------------------------------------------+---------+--------+
I0804 18:42:40.465586 93 tritonserver.cc:2483]
+----------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Option | Value |
+----------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| server_id | triton |
| server_version | 2.41.0 |
| server_extensions | classification sequence model_repository model_repository(unload_dependents) schedule_policy model_configuration system_shared_memory cuda_shared_memory binary_tensor_data parameters statistics trace logging |
| model_repository_path[0] | /opt/ml/model/ |
| model_control_mode | MODE_EXPLICIT |
| startup_models_0 | ensemble_model |
| strict_model_config | 0 |
| rate_limit | OFF |
| pinned_memory_pool_byte_size | 268435456 |
| cuda_memory_pool_byte_size{0} | 67108864 |
| min_supported_compute_capability | 6.0 |
| strict_readiness | 1 |
| exit_timeout | 30 |
| cache_enabled | 0 |
+----------------------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
I0804 18:42:40.465919 93 sagemaker_server.cc:293] Started Sagemaker HTTPService at 0.0.0.0:8080
I0804 18:42:41.676092 93 sagemaker_server.cc:190] SageMaker request: 0 /ping
I0804 18:42:46.643633 93 sagemaker_server.cc:190] SageMaker request: 0 /ping
...Note that even though we can run Triton both HTTP and GRPC endpoints locally, when deploying via SageMaker Inference, its running only a HTTP service on port 8080.
In the next post, I will be showing an example of how to test and invoke the provisioned endpoint.